Vigil Intel · Founder, Product Architect, and Engineer · 2026
Developing MENA-native AI risk intelligence specifically for GCC investors and strategy teams.
Designed and built Vigil Intel, a multi-LLM geopolitical risk intelligence platform providing traceable, source-grounded analysis for GCC decision-makers at the required decision-making speed.
Executive Snapshot
- Identified a gap for GCC investors, family offices, and strategy teams who required faster, more traceable MENA-native geopolitical risk intelligence than traditional reports or ad hoc AI workflows offered.
- The core issue was not data availability, but signal trust. Institutional analysts must trace reasoning, verify sources, and identify which model generated each risk score. Without an audit chain, outputs are unsuitable for investment decisions.
- I prioritized Vigil Intel as a risk pipeline, not just a data product, designing a multi-LLM Council architecture that separates authoring and verification to enhance traceability, reliability, and buyer trust.
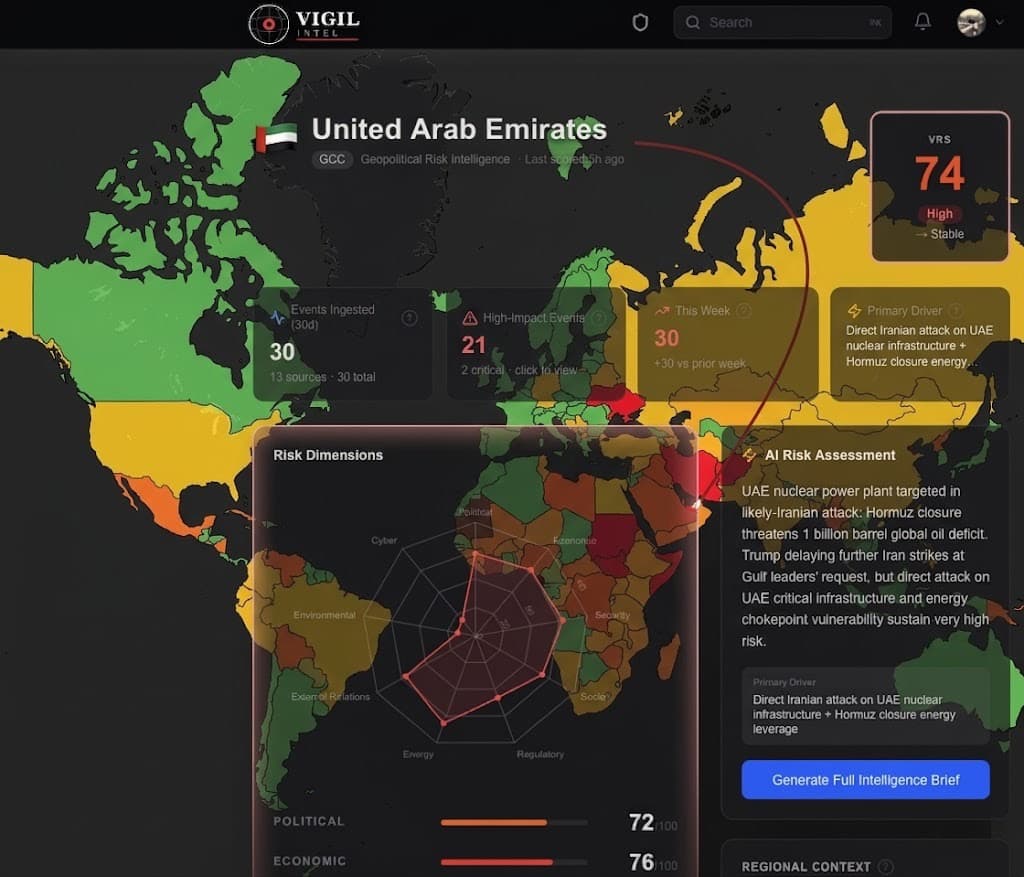
- The platform covers 168 countries across 9 proprietary risk dimensions, with enhanced depth for 32 GCC and MENA priority markets. It features monitored data pipelines from over 50 curated sources, recovery logic for source failures, and live Stripe monetization.
- Vigil Intel launched in 6 weeks from concept to production and is currently a founder-built proof-of-architecture with monetization enabled for design-partner engagement.
The Challenge
In early 2026, increased geopolitical volatility in the Gulf led investors to reassess capital exposure and country risk. Regional analysts relied on risk agency reports, manual workflows, and ad hoc AI outputs, which often took days to produce. By the time analyses were delivered, conditions had already changed.
The issue was not data, but signal trust. When an AI system reports a country's risk score change, analysts must understand the rationale, trace the source, and determine if other models concur. Without an audit chain, outputs cannot support investment decisions.
The constraints were clear: build independently, without a team or inherited codebase, within six weeks, and deliver output suitable for professional risk practitioners. The platform needed to be credible, traceable, and usable from day one.
My Mandate
- Served as sole product owner, architect, and engineer, responsible for all decisions from system design to user experience.
- Designed a reliability architecture that institutional buyers could trust without external validation.
- Built 9 proprietary risk dimensions calibrated for the GCC and MENA region.
- Constructed self-maintaining data pipelines across more than 50 curated primary sources.
- Shipped a live production platform with Stripe monetization within 6 weeks.
What I Changed
Integrated verification into the core architecture.
The Brief Guardian design separates authoring (Sonnet) from verification (Opus), ensuring verification cannot access its own authoring output. No brief is published without independent review, establishing an audit chain for institutional-grade output.
Replaced the initial verification architecture in week four.
The first version returned only APPROVED or REJECT, discarding valuable partial outputs and causing unnecessary delays. I rebuilt verification to return APPROVED or REVISION_REQUIRED with specific feedback, enabling iterative improvement before publication.
Prioritized source quality over quantity.
The platform uses over 50 curated primary sources, avoiding aggregator sites and secondary news. This approach trades broader coverage for traceable, verifiable intelligence.
Deferred caching infrastructure until usage data was available.
Building caching before identifying repeat queries adds unnecessary complexity. Implementation waited until real usage patterns emerged.
Key Decisions and Tradeoffs
LLM Council: separate author and judge.
No single model should both author and verify its own output. The Brief Guardian reviews every brief and blocks publication until it passes independent review.
Tradeoff: Higher pipeline complexity and latency compared to single-model generation.
Executive signal: Output reliability was prioritized as a primary product requirement from the outset.
Replaced v1 of the verification architecture.
The binary APPROVED/REJECT structure caused unnecessary blocking for borderline outputs. I identified this flaw in week four and rebuilt the verification layer with revision feedback, accepting a week of rework within the six-week timeline.
Tradeoff: One week of rebuild time within the overall constraint.
Executive signal: I prioritized correctness over delivering a flawed architecture.
Source quality over quantity.
50+ primary sources instead of broad aggregation. No secondary news or aggregator sites. For institutional risk intelligence, source traceability is more important than coverage volume.
Tradeoff: Narrower coverage for greater source credibility.
Executive signal: Traceable sources are a trust requirement for institutional output.
Results and Validation
- Live at vigil-intel.com
- Shipped in 6 weeks from concept to live production
- Covers 168 countries across 9 proprietary risk dimensions
- Includes enhanced monitoring depth for 32 GCC and MENA priority markets
- Uses 50+ curated primary sources with monitored recovery logic for source failures
- LLM Council architecture operating in production with independent verification
- Stripe monetization is live across Basic, Pro, and Elite tiers
- Currently positioned for design-partner validation with GCC risk, strategy, and investment teams
What This Proves
This case demonstrates end-to-end AI product judgment at an institutional level: designing a multi-LLM reliability architecture from first principles, identifying and correcting structural flaws under time pressure, and delivering a production platform that meets institutional trust requirements. The architectural decisions, separating authoring from verification, prioritizing source quality, and deferring infrastructure, are directly transferable to sovereign AI programs, enterprise GenAI platforms, or AI governance mandates requiring institutional reliability.
Lessons Learned
- Signal trust is a design decision, not a feature. The Brief Guardian pattern addresses institutional trust requirements for LLM-based risk systems. Integrate it from the outset.
- Eliminate architectures that create structural problems. The v1 binary verification approach was flawed. Identifying and rebuilding it in week four was the correct decision, even within a six-week window.
- Defer infrastructure decisions until usage data informs development. Implementing caching and query optimization before real usage patterns emerge adds unnecessary complexity.